Copyright Sucks
2022 January 25Today I saw this amazing story on twitter about a report that google had flagged a file in google drive as "containing copyright infrigement". The catch? The file only contained a single "1" in it.
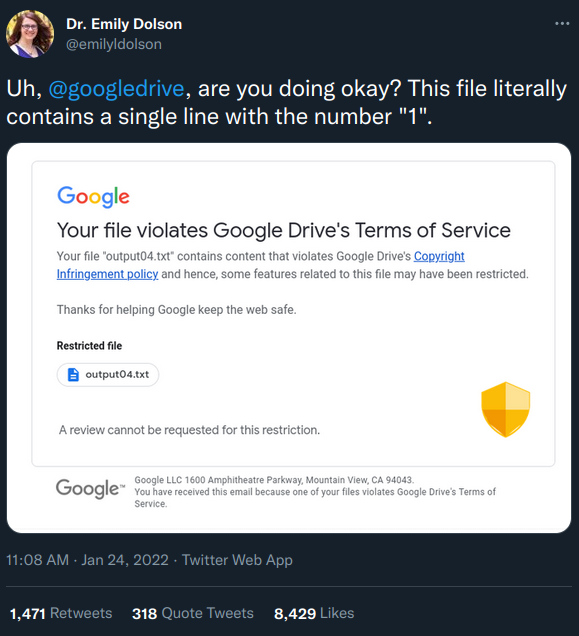
Abuses of automatic copyright detection are not rare (specially on youtube), but this reached new heights of stupidity. Someone in a thread on hackernews tried creating files with single numbers randomly sampled between -1000 and 1000, and found that several of the numbers triggered the automated response.

For me, what this story highlights is the power imbalance on the internet. A person publishes one copyrighted file or video, by mistake, and they could have their data seized and/or deleted from various services, without redress or resource, quite possibly causing a lot of damage to them. On the other hand, corporations like google regularly make stupid mistakes like these, and nothing happens to them. This makes me so tired.